
关注官方文档:
Home - Apache Hive - Apache Software Foundation
上一张最经典的Hive架构图:
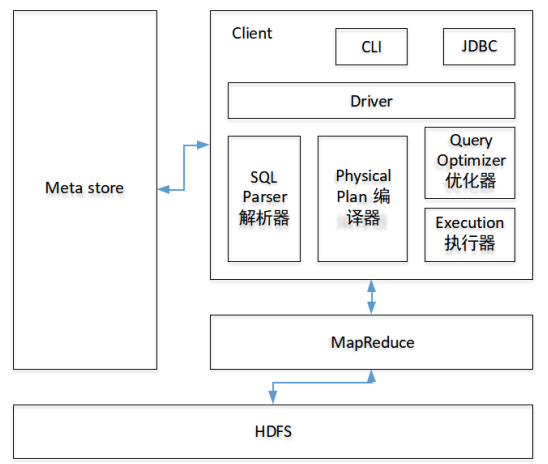
其中出现了几个关机的模块
- Meta store
- Client
- MapReduce
- HDFS
理解了上面几个关键模块,也就理解了Hive的架构:
Meta store
玩大数据一定要知道什么叫元数据(Meta store),
元数据就是描述数据的数据。听起来有点绕口,但一定要理解。何为描述数据的数据?举个例子,我们拿到了一批用户数据,这些数据包含了2021年至2023年的上海市的抽烟男性数据。上述对这些数据描述的信息就是元数据。具体到数据里面,可能会先把这些用户具体的数据存储到存储引擎,2021年至2023年的上海市的男性抽烟数据 描述这个数据的信息放到元数据信息里。
Hive选择使用MySQL来存储元数据,也就是将真实的存储数据放到了底层(下面讲的HDFS),将描述这些数据的信息放到了MySQL里。
Client
MapReduce
HDFS
放在最下面的是数据存储模块,Hive选择了使用HDFS来进行底层数据的存储,所以选择了Hive,也就选择了Hadoop。